Compatible Course Content Synchronization Model for Various LMS over The Network
Get 1000000 0FP0EXP Token to remove widget entirely!
Get 500000 0FP0EXP Token to remove my NFTS advertisements!
Special Seminar, 21 November 2016, Engineering Building Room B
Note
- Author: Fajar Purnama
- Affiliation: Human Interface Cyber Communication (HICC) Laboratory
- This is an essay published in Tokubetsu Enshuu / Tokuen which is a Special Seminar on Computer Science and Electrical Engineering between Master’s student. First semester students only needs to listen and discuss, second semester students have to present other researcher’s publication related to their research, third semester students have to present progress of their research, and fourth semester students only needs to listen and discuss. This is my research progress during on my third semester of Master’s.
- The original is available at Reasearch Gate.
- The presentation is available at Slide Share.
- The source code is available at Github.
Abstract
The release of massive open online course (MOOC) allows the delivery of course to anyone almost anywhere around the globe, and mostly freely distributable. However there is a connectivity issue on developing countries that limits the availability of MOOC. A solution to this issue was distributed learning management system (LMS). One of the challenges is how to distribute the learning contents effectively, one example is how to distribute with the lowest possible network data cost. Unfortunately, there is still a problem that the learning content distribution is not one time only, but continuous. Like in universities it always changes or revised almost every semester with the goal of improving education quality. Without a defined method a whole content is distributed each time causing large network traffic, however there is a way to only distribute the revised part through a recent introduced term course content synchronization. This fixes the problem but there is still another challenge to course content synchronization application which is the compatibility issue that the first application only works for Moodle 1.9. On this work is proposed a model that will be compatible to most LMS. The proposed model exports the course contents into a backup file or an archive, after that performs an incremental file synchronization between the two archives. The experiment was conducted on few LMSs which are Moodle, Atutor, Chamilo, Dokeos, Efront, and Illias to test it compatibility. In the end it worked on these LMSs and the result showed lower network traffic compared to without using the course content synchronization.
1. Introduction
The number of ways how courses are delivered varies due to the development of technologies. When electronic devices were embedded in education a specified learning and teaching method e-learning (electronic learning) was introduced. Then the advanced of information communication technology (ICT) made it possible to deliver courses online. For each person to own an electronic device connected to the Internet can follow a course anywhere at anytime. Now with MOOC anyone from all over the world can join an online course, with unlimited participants, since it is open access via the web. All of these grants more people to be able to access education.
Without any problems, no doubt that everyone will be able to utilize online course. However not all regions have the required ICT infrastructure to access online courses smoothly since people are wide spread, where some are far away from the service’s location, on [1] they have to rely on GPRS network. In other words some people are facing network connectivity issues, mostly in developing countries. In survey result [2] the biggest complains of students in following online course is the limited network bandwidth. Our peers research [3] [4] suggested that the necessary accessibility is needed in order to keep the motivation of the students and teachers. One way to deal with this problem is to distribute the service in more locations than relying on a centralized service that causes bottlenecks. As on [5] is stated as the third generation of content management system (CMS), thought on this work is more about learning contents of LMS than general contents of CMS. Having a distributed LMS increases the availability of the online course where people access the service on their local area than on the central area.
Even after the distributed LMS was implemented, there was still more to do. The fact that learning contents are not distributed only once, but many times and continuously causes high network traffic and needs a method to reduce the cost. The continuous distribution is because the contents goes through countless revisions and usually distributed everytime it is revised. Usually the copy and replace is applied where the subscribers deletes the old contents and downloading the new one as on Figure 1. Since it is common trend the data size of the contents increases with every revisions, the data the subscribers have to download every time increases. It will be either facing a high network traffic or bare with outdated contents.
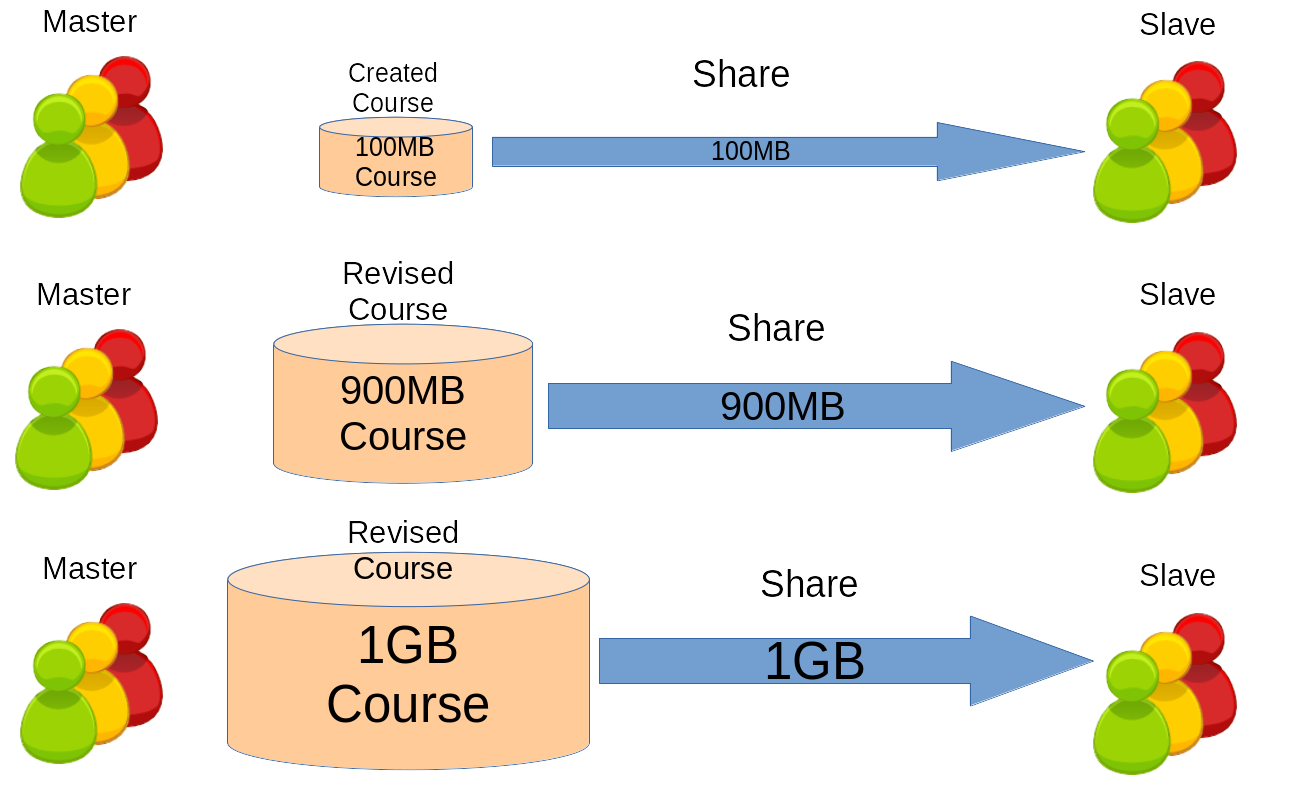
Figure 1. The issue to course sharing when there are many revisions. The subscribers will always have to redownload everytime a course is revise. On this figure is shown that subscribers initially download 16 MB of course contents, then 28 MB, 30 MB, and eventually increases which will cause heavy network traffic.
A term that was recently introduced dynamic content synchronization (here is course content synchronization because focusing on course) [6] provides a method to reduce a network cost. The method is incremental data synchronization where with this method, it is no longer necessary to re-download the whole contents whenever it is revised, but download only the revised part illustrated on Figure 2. To put it simply, instead of throwing away the outdated contents and retrieving the new one, it is more network efficient to update the outdated one. Although there are more to dynamic content synchronization (i.e. filtering private data, collaborative content building, etc) on this work it is only discussed the incremental data synchronization where on the subscribers side is to retrieve only the necessary data to minimize the network data cost.
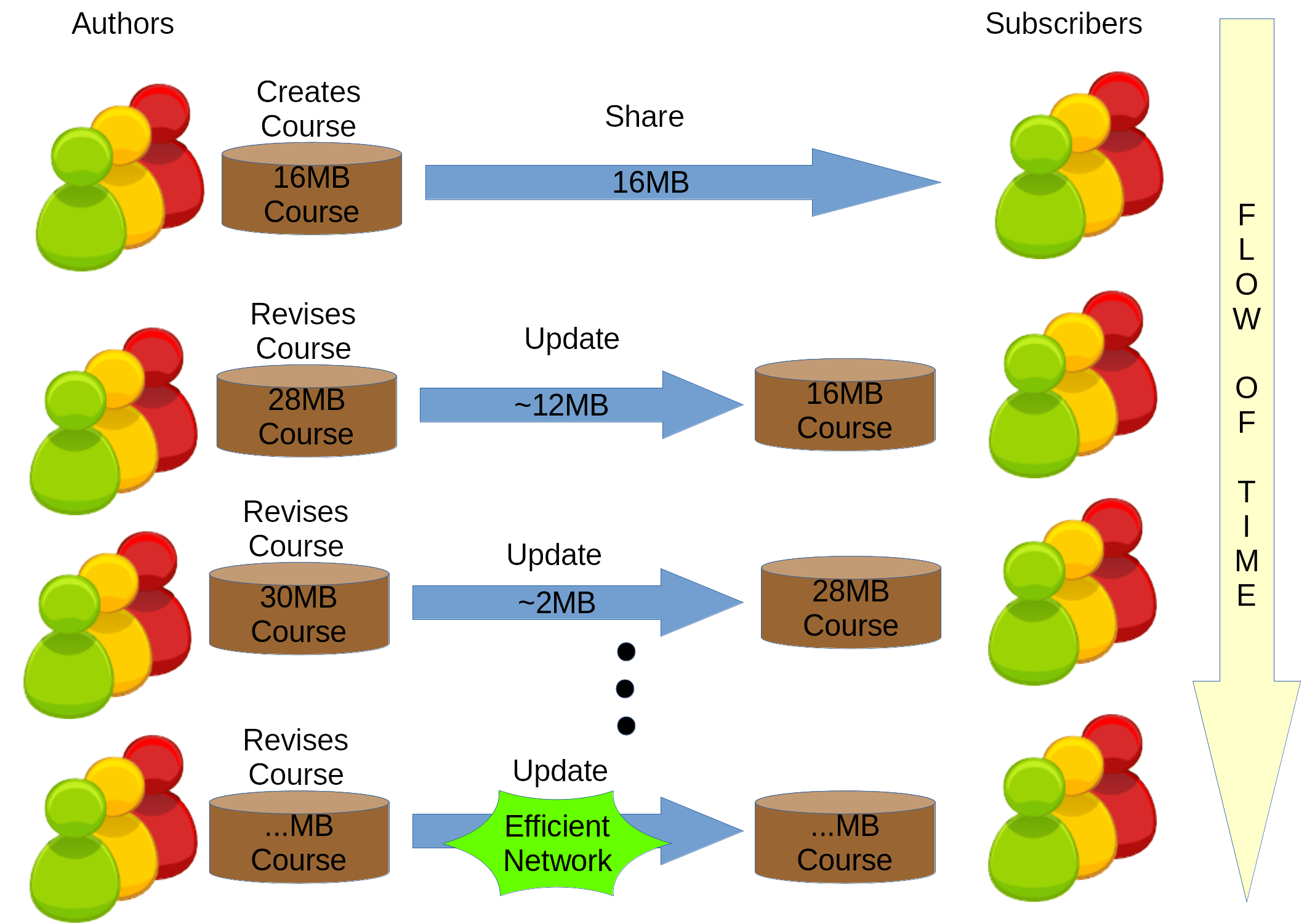
Figure 2. Incremental data synchronization illustration between course contents. The subscribers will initially download 16MB of course contents. When the authors revised the course to 28MB the subscribers will only needed to download the revised part which is around 10MB. Then revised to 30MB and only needed to get around 2MB and so on which will show lighter network traffic compared to Figure 1.
The benefits of incremental data synchronization on distributed LMS were already discussed on the previous work [6]. On the other hand this work discussed one of the aspects that needs to be improved on the previous work. The main aspect is the compatibility to all LMS and its versions, where the first application was only compatible to Moodle version 1.9, then 2.x [7]. It was already introduced a model to extend its compatibility on this introductory work [8] showing compatibility up to Moodle 3.x. However the introductory work focused only on Moodle, while on this work will generalize the model for all existing LMSs (other than Moodle). The objective of this work is to develop a course content synchronization model that is compatible to most existing LMSs.
2. Related Work
Sharing a course content became popular ever since MOOC was introduced. Periodical course Moodle on MOOC teaches students how to use Moodle and advised them to share their finished course [9]. Sharing helps other instructors who are not yet experienced in developing their own course, because making an own well designed and written one may take a lot of time. Some specialized course may only be written by experts. Course content sharing reduced the burden of the teacher and MOOC gave more students from all over the world a better chance to access a quality education.
Distributed LMS is another form of course sharing where the course contents are shared to other servers on other regions. The typical way of course content sharing is dump, copy, then upload. Most LMS have a feature to export their course contents into an archive and allows to import the contents to another server which have the LMS. The technique to export and import varies to systems but the concept is to synchronize the directory structure and database. There is a very high demand for this feature that it is still improving until now, for example being able to export user defined part of the contents is being developed. Other CMS and LMS that currently doesn’t have this feature will be developed as it is stated on its developer forum.
b. Dynamic Content Synchronization
Sharing course contents temporary solves the problem of creating course contents by oneself, but forgotten the fact that most will go through countless revisions. There was always the choice to ignore the updates, but that goes against the goal of having a better education, which is why contents are constantly revised. If chosen to keep up to date, then prepare to face heavy network traffic (quite an issue for developing country but might not be a problem for developed countries with high Internet connection speed). Thus a term was created to address this issue, which is dynamic content synchronization.
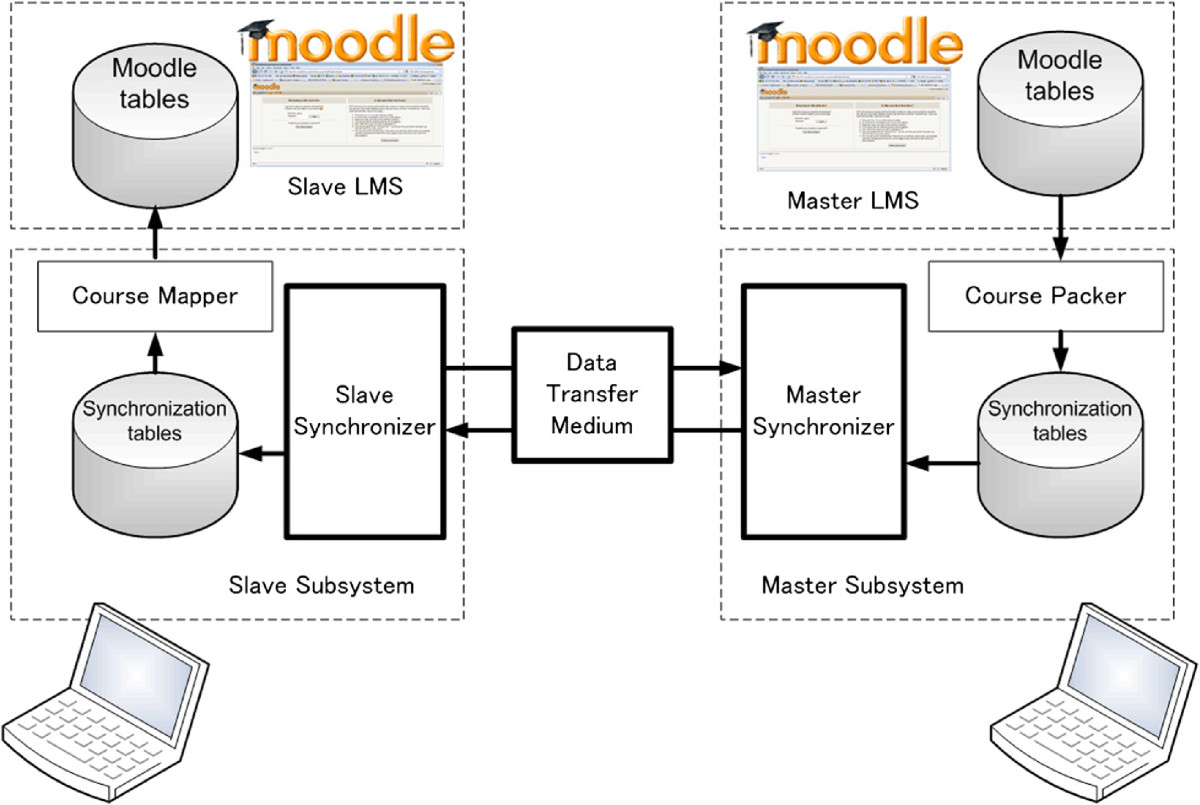
Figure 3. Dynamic content synchronization model for Moodle, both Moodle tables are converted into synchronization tables. Then the synchronization checks for inconsistency between the two tables which in the end applies the difference between both synchronization table to the slave’s synchronization table. Finally the synchronization table is re-converted into Moodle table and that is how it is synchronized. [10]
Early it was introduced as Moodle synchronization [10], then as dynamic content synchronization on distributed LMS [6] [7]. Within the dynamic content synchronization there is a method called incremental data synchronization which allows to retrieve the revised part only than the entire contents. The method synchronizes the directories and databases that can be shown on Figure 3 which in the end reduces the network data cost of the content distribution. However this is not the only feature that was discussed, it also involves how to filter private data, and many other aspects of synchronizing learning contents which consists of assignments, discussion forums, materials, quizzes, scores, etc. On this work it is called course content synchronization because it only focuses on the course contents.
c. Incremental Data Synchronization
Before there was incremental data synchronization there was patch. Software developers tends to develop their softwares frequently as their softwares’ version increases everytime. Users can just abandoned the old version softwares and get the new one, but to make it more efficient, software developers invented the patching system. They create patch by calculating the difference between the old and the new software, and that difference itself is the patch. Rather than copy and replace, a patch can be applied on old version software to be updated into the new version. This is less data costly because an ideal patch is always less the data size of the full software itself.
To generate a patch it is needed both version of the software in that same machine, but what happens if the softwares are in different machines? In other words, it is desired a user to create a patch themselves, simply saying, self update. It was then that incremental data synchronization was invented. It is commonly as incremental file synchronization, the term data is only to show that it applies also to other than files. The research [11] attempted in generating a patch when both old and new file are on different machines, where the patch will be generated on a server that had the new file and will be given to the client that had the old file which will be transformed into the new file. It is called the rsync algorithm where more details are explained as follow:
- A signature of the old file will be generated on the client side. The signature consists of strong and weak checksums of every defined allocated piece of the file. It is said to be a reference of the old file.
- The signature is sent to the server, and the server will use the signature to produce a delta/patch. The checksums of every defined allocated piece of the new file is compared with the signature’s checksums. First it checks the weak checksum, and if they are same it will check the strong checksum to see if both piece are truly identical. Second all new pieces found on the new file will be put into the delta. Third generate instructions on the delta for the old file to re-arrange the identical pieces to be at the same position as the new file, input the new pieces into the right location, and delete pieces on the old file that is not found on the new file.
- The delta/patch is sent to the client and to be applied on the old file which result in generating the new file which will be identical to the one on the server.
3. Method
a. Course Content Synchronization Model
The previous application also handles the database and directory synchronization which is why a new application must be created for each LMS and everytime their structure changes. This is not really a problem, but this work found a better model that one application can apply to all LMS and will not be affected by the change of LMS version. Most LMS are able to export their directories and database contents and its information, which later on can be imported to another server. The model on Figure 4 shows to let the LMSs’ export and import feature to handle the database and directory, then perform incremental data synchronization between the two exported archive.
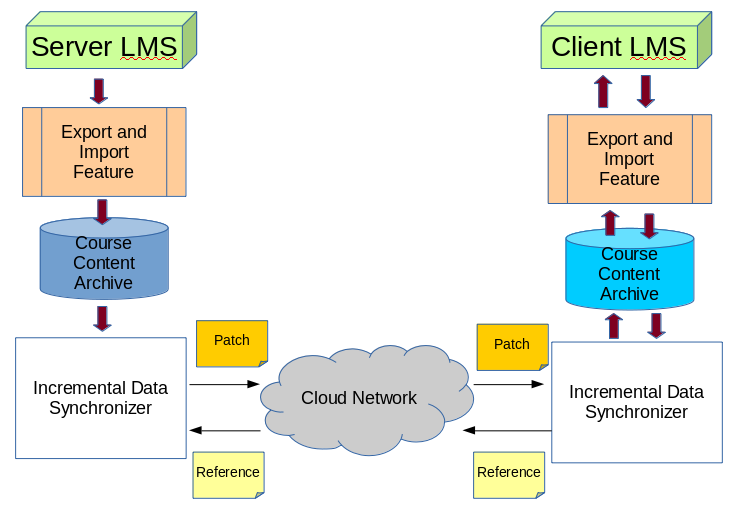
Figure 4. Proposed course content synchronization model, both LMS will export their course contents into an archive. Then perform incremental data synchronization between the archives. The client will send a reference to the server, and the server will return a patch to update the client’s course content archive, and later on to be imported back to the client’s LMS.
The incremental data synchronization is to calculate the difference between the two archives and apply that difference to the client’s course content archive, updating it to the latest version as the one on the server. There are many existing applications capable of performing incremental data synchronization, and this work will be using rdiffdir application based on rsync algorithm. Based from the previous section about incremental synchronization, the procedure can be illustrated on Figure 5 and can be explained as following: (1) the client will generated a signature of its course content archive and sends it to the server, (2) the server will use the received signature to its course content archive to generate a delta and returns it to the client, (3) the client will apply the received delta to its course content archive making it identical to the course content archive on the server. Importing this course content archive will update the course contents on the client’s LMS.
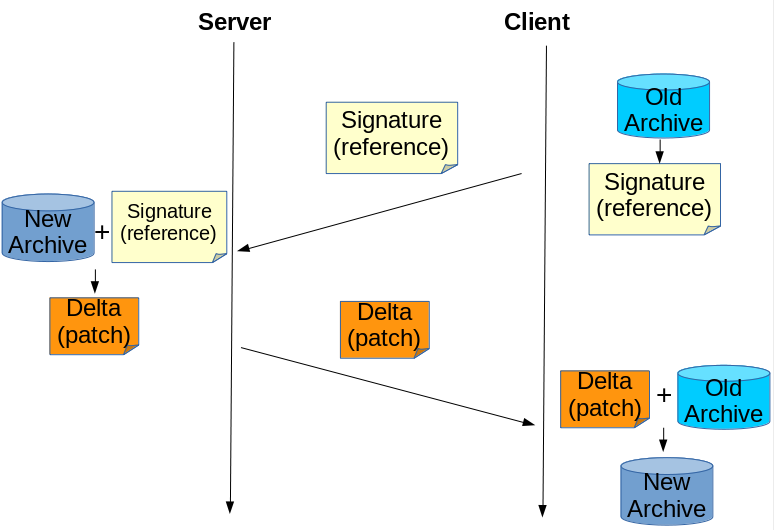
Figure 5. Incremental synchronization between course content archives based on rsync algorithm. First the client generates a signature and sends it to the server. Second the server generates a delta and sends it to the client. Third the client patch its archive into the latest version.
b. Experiment
The purpose of the experiment is to compare the network traffic of course distribution after revisions between without using any defined method and using this method (course content synchronization). In order to show the model’s compatibility, the experiments will take place on many LMS, which are Moodle, Atutor, Chamilo, Dokeos, Efront, and Illias. The end result should show the network traffic in data rate (Bytes/seconds), and whether it is implementable for the experimented LMS.
Figure 6. A snapshot of computer network course design which consists of many materials, discussion forums, assignments, and quizzes.
The experiment consists of four different scenarios. The first is without synchronization, the second is large content synchronization, the third is medium content synchronization, and the fourth is synchronization where both sides have identical course contents (no update). Since there are six different LMS, it is too much to discuss all the network traffic, but instead it will be summarize to the average. The term large and medium content is a self defined term based on the difference of both course contents between client and server.
| LMS | 1 Topic | 2 Topics | 3 Topics |
|---|---|---|---|
| Moodle | 16.5 MB | 28.4 MB | 30.5 MB |
| Atutor | 336.5 kB | 11.7 MB | 13.7 MB |
| Chamilo | 8.5 MB | 20 MB | 22 MB |
| Dokeos | 27.4 MB | 39 MB | 41 MB |
| Efront | 16.5 MB | 28 MB | 30 MB |
| Illias | 430.3 kB | 22.8 MB | 26.6 MB |
The experiment uses the authors own original course contents which mainly consists three topics are computer programming, computer network, and penetration testing, with each consists of materials, discussion forums, assignments, and quizzes, a snapshot of one of the topics can be seen on Figure 6. Large content synchronization is when the client only have one of the three topics (example for Moodle will update from 16.5 MB to 30.5 MB), while medium content synchronization is when the client already have two of the three topics (example for Moodle will update from 28.4 MB to 30.5 MB), and the client wants to synchronize to the server in order to have all three of the topics (update). On Table 1 shows the course content data size in bytes when it has one, two, or three of the topics. The data sizes varies depending on the LMS, but the contents such as materials, discussion forums, assignments, and quizzes are almost exactly similar.
c. Demonstration
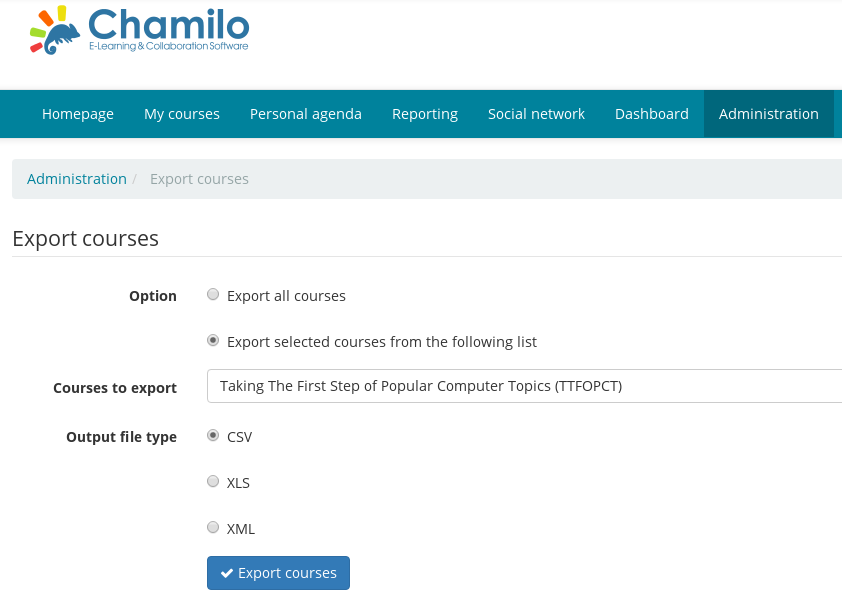
Figure 7. Chamilo course export interface showing the option to export courses in form of .csv, .xls, or .xml.
The experiment consists of three main steps. The first step is to export the course contents into an archive or it can also be called a backup file. An example of an LMS’s course backup interface can be seen on Figure 7. Some have a very powerful backup features such as allowing to choose which parts of the contents to backup and including students’ informations or not like Moodle, but most LMS have only a simple backup interface which can only backup the running course as it is. There are still other LMS that does not have this feature for example FormaLMS which makes Figure 5 irrelevant, but a strong reason why it is still proposed because this feature has a high demand that the developers of these LMS states that they will make it available in the future.
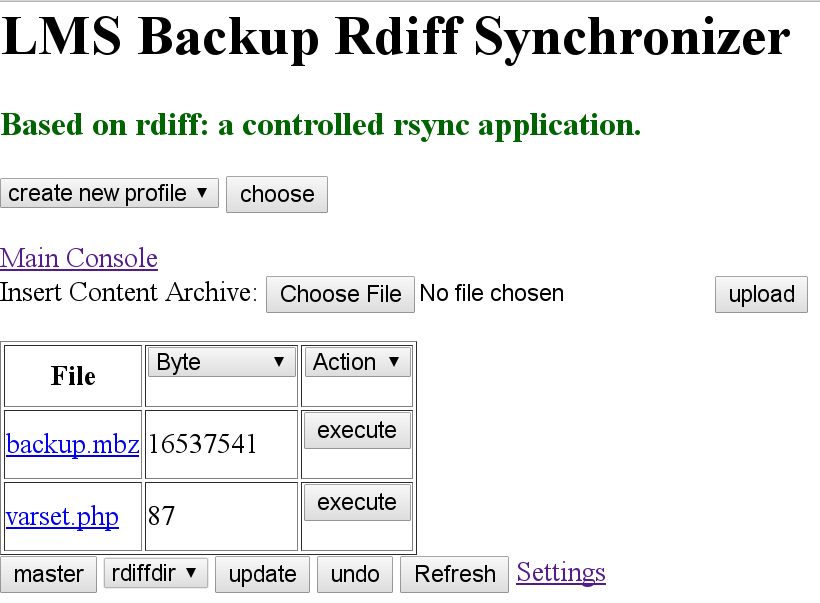
Figure 8. The synchronization application where the user inserts the course contents archive around 16MB. If this is the server side then simply press the master button, or else press the update button.
The second step is to perform an incremental data synchronization between the two archives in order to update the client’s archive to the version of the server’s archive. This work made a web application to utilize rdiffdir application online which the interface can be seen on Figure 8, the full source code of the application is available on [12]. Basically it follows Figure 5, it can make a signature of the course content’s archive and upload it to the server which then the server will automatically respond by creating a delta based on the received signature and invoking the client to download it, later in the end patch client’s archive using the received delta. Finally Figure 8 will turn into Figure 9.
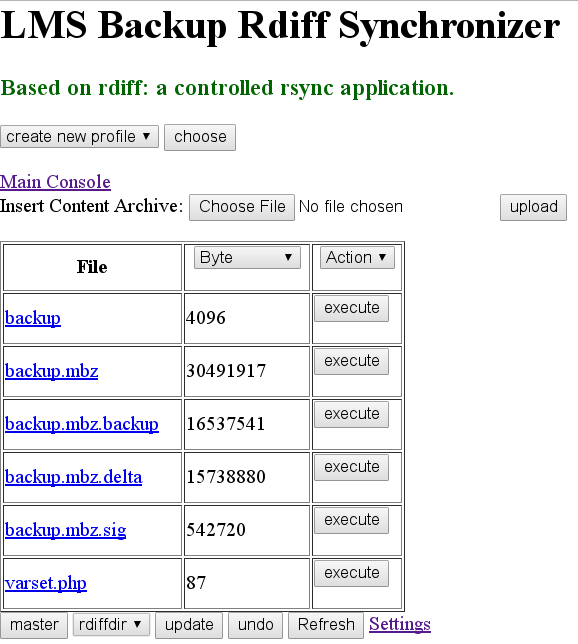
Figure 9. Synchronization interface after performing update showing that it generated a signature around 5MB, and receiving a delta around 16MB, updating the backup.mbz to around 30MB.
Exporting and importing the archive on the LMS is done manually but additional features can be added on the web application to do this automatically. Outside of this work however, performing an incremental data synchronization is not limited to use this work’s web application. Existings applications such as git, svn, dropbox, google drive, and others that can do an incremental data synchronization can be used by modifying the interfaces to the administrators needs. What this work proposed is the model on Figure 4, while Figure 5 is just one way of performing incremental data synchronization which is not absolute and can be changed as long as the end result is met.
The third step is importing the synchronized archive back into the client’s LMS. This is done to see whether if importing is possible and to see whether the client’s contents is up to date to as the one on the server. This is to verify if the synchronization succeeded where the previous two steps became pointless if this step fails.
4. Result
Table 2 showed that this method worked on the LMSs that was tested on where on the experiments, the synchronized content archive were successfully re-imported on the LMS. The produced network traffic is provided on Figure 10 which consists of uplink and downlink. The uplink is affected by the signature’s size on Table 3 which is common to be around a few megabytes and usually least contributed to the network traffic, though there is a manuscript that gives mathematical calculations of the size of the signature. The downlink is affected by the size of the delta on Table 4 which consists of new contents for the client and sets of instructions, mostly represents the revised part of the content and greatly contributes to the network traffic.
| LMS | Synchronization |
|---|---|
| Moodle | √ |
| Atutor | √ |
| Chamilo | √ |
| Dokeos | √ |
| Efront | √ |
| Illias | √ |
| LMS | Large Sync | Medium Sync | No Update |
|---|---|---|---|
| Moodle | 0.54 | 0.97 | 1.16 |
| Atutor | 0.03 | 0.31 | 0.37 |
| Chamilo | 0.22 | 0.54 | 0.61 |
| Dokeos | 1.31 | 1.63 | 1.68 |
| Efront | 0.1 | 0.17 | 0.19 |
| Illias | 0.02 | 0.13 | 0.16 |
| LMS | Large Sync | Medium Sync | No Update |
|---|---|---|---|
| Moodle | 15.74 | 2.97 | 0.72 |
| Atutor | 13.53 | 2.09 | 0.07 |
| Chamilo | 14.43 | 2.62 | 0.2 |
| Dokeos | 15.09 | 3.65 | 0.96 |
| Efront | 13.65 | 2.14 | 0.01 |
| Illias | 26.22 | 4.01 | 0.00001 |
The main discussion is on Figure 11 which shows the average total network traffic (uplink addition to downlink) of the synchronization and without synchronization. It is clearly shown that using synchronization is less costly than without using synchronization, because without using synchronization involves retrieving the whole course contents while using synchronization only retrieves new parts of the course contents although that involves sending reference in oder to determines which parts to be retrieve and resulting some instructions to rearrange the existing contents and deleting some that is supposed to be deleted. This method is particularly efficient when there are often small revisions, for this case compared to retrieving ~28MB, it is only needed to retrieve ~3MB, which is ~10 times smaller, although it is still efficient when large revision occurs. There is possibly a case that synchronization on a very large revision can be more costly than without using synchronization, and incremental data synchronization may fail on certain archives, but for now they are out of the scope of this work and it is less likely to happen.
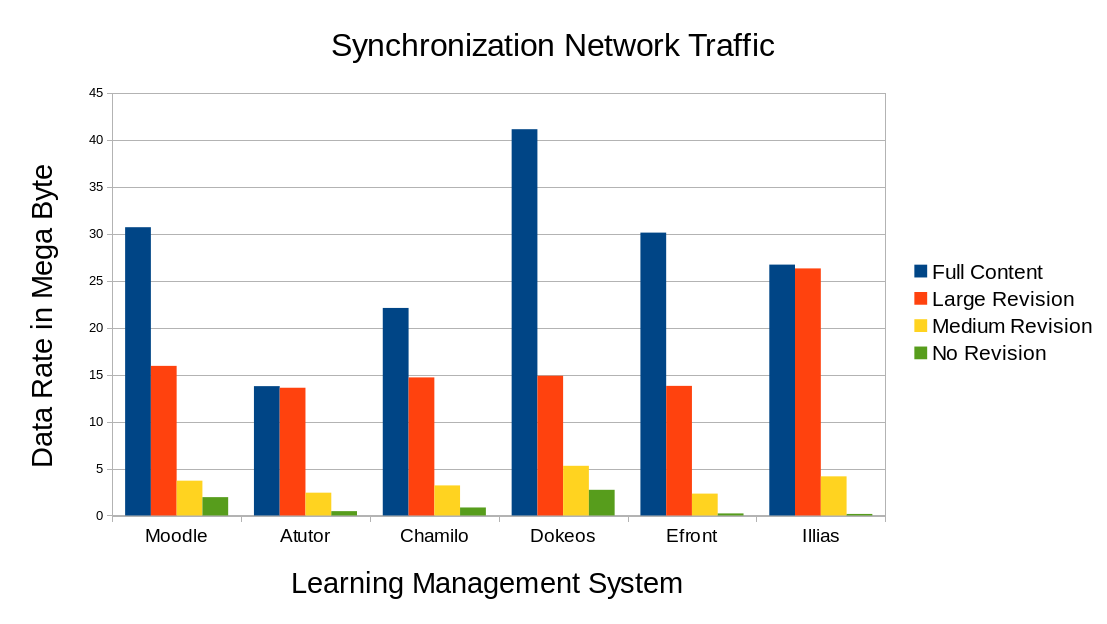
Figure 10. Network traffic produced during synchronization of course content archives from 6 different LMS conducted on different scenarios.
5. Conclusion
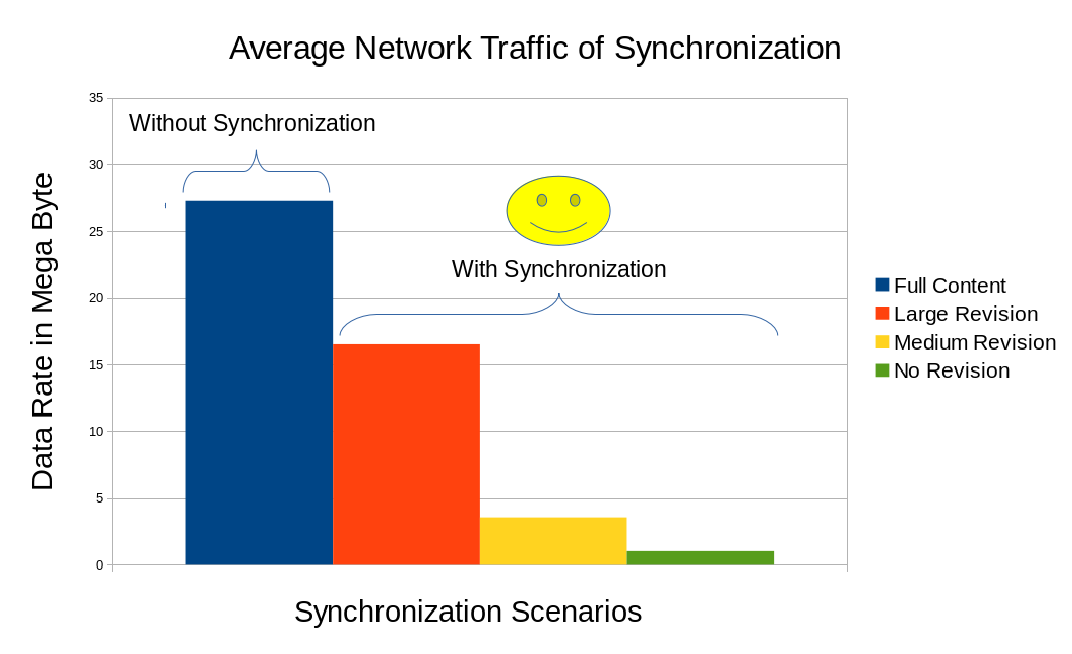
Figure 11. Average network traffic of Figure 10 showing that using synchronization produced less network traffic than without using synchronization which is a better option.
The proposed online course content synchronization model worked on the six LMSs that was experimented on this work indicated by the success of re-importing the course content archives after it went through the synchronization process which showed that the contents have been updated. This compatibility was achievable because the model took advantage of the export and import feature that is available on the LMSs. The incremental data synchronization which on this work utilizes rdiffdir showed efficient network usage that attempted to retrieve the revised part of the contents only. Utilizing this work will reduce the burden of course content distribution on the network.
6. Future Work
The method were tested on six LMSs on this work and testing on more LMSs is encouraged. For current existing LMSs that are still not compatible, will be build an export and import feature to make it compatible. Furthermore this work focuses only on the incremental data synchronization, which the other part of course content synchronization, which is privacy and security becomes future work, that is needed to complete this application. The final step takes on real implementation of this application which includes aspects such as the ease of use of this application, and how it benefits the development and distributions of course contents.
7. Reference
- Linawati, “Performance of mobile learning on gprs network,” Teknologi Elektro Journal, vol. 11, no. 1, pp. 1–6, 2012
- N. S. A. M. Kusumo, F. B. Kurniawan, and N. I. Putri, “Learning obstacle faced by indonesian students,” in The Eighth International Conference on eLearning for Knowledge-Based Society, Thailand, Feb. 2012.
- S. Paturusi, Y. Chisaki, and T. Usagawa, “Assessing lecturers and student’s readiness for e-learning: A preliminary study at national university in north sulawesi indonesia,” GSTF Journal on Education (JEd), vol. 2, no. 2, pp. 1–8, 2015.
- H. T. Sopu, Y. Chisaki, and T. Usagawa, “Use of facebook by secondary school students at nuku’alofa as an indicator of e-readiness for e-learning in the kingdom of tonga,” International Review of Research in Open and Distributed Learning, vol. 17, no. 4, pp. 203–223, 2016.
- Q. Li, R. W. H. Lau, T. K. Shih, and F. W. B. Li, “Technology supports for distributed and collaborative learning over the internet,” ACM Transactions on Internet Technology (TOIT) Journal, vol. 8, issue 2, no. 5, pp, 2008.
- R. M. Ijtihadie, B. C. Hidayanto, A. Affandi, Y. Chisaki, and T. Usagawa, “Dynamic content synchronization between learning management systems over limited bandwidth network,” Human-centric Computing and Information Sciences, vol. 2, no. 1, pp. 1–17, 2012.
- T. Usagawa, M. Yamaguchi, Y. Chisaki, R. M. Ijtihadie, and A. Affandi, “Dynamic synchronization of learning contents of distributed learning management systems over band limited network contents sharing between distributed moodle 2.0 series,” in International Conference on Information Technology Based Higher Education and Training (ITHET), Antalya, Oct. 2013.
- F. Purnama, T. Usagawa, R. M. Ijtihadie, and Linawati, “Rsync and Rdiff Implementation on Moodle’s Backup and Restore Feature for Course Synchronization over The Network,” in International Conference IEEE Region 10 Symposium (TENSYMP), Bali, Indonesia. 2016.
- M. Cooch, H. Foster, and E. Costello, “Our mooc with moodle,” Position papers for European cooperation on MOOCs, EADTU, 2015.
- T. Usagawa, A. Affandi, B. C. Hidayanto, M. Rumbayan, T. Ishimura, Y. Chisaki: Dynamic synchronization of learning contents among distributed moodle systems. 2009. JSET, pp 1011–1012.
- A. Tridgell and P. Mackerras, “The rsync algorithm,” The Australian National University, Canberra ACT 0200, Australia, Tech. Rep. TR-CS-96-05, Jun. 1996.
- 0fajarpurnama0/file-synchronizer-online-course-sharing. [On-line]. Available: https://github.com/0fajarpurnama0/file-synchronizer-online-course-sharing. [Accessed 12 November 2016]
- S. Li, Q. Zhang, Z. Yang, and Y. Dai, “Understanding and Surpassing Dropbox: Efficient Incremental Synchronization in Cloud Storage Services,” in IEEE Global Communications Conference (GLOBECOM), 2015.
Mirrors
- https://www.publish0x.com/fajar-purnama-academics/compatible-course-content-synchronization-model-for-various-xkkqpmn?a=4oeEw0Yb0B&tid=github
- https://0darkking0.blogspot.com/2020/10/compatible-course-content.html
- https://medium.com/@0fajarpurnama0/compatible-course-content-synchronization-model-for-various-lms-over-the-network-c42d944a11a4?sk=d55ec53f6f335e38fdadb27609a9c89b
- https://0fajarpurnama0.github.io/masters/2020/10/14/course-synchronization-various-lms
- https://hicc.cs.kumamoto-u.ac.jp/~fajar/masters/course-synchronization-various-lms.html
- https://steemit.com/computers/@fajar.purnama/compatible-course-content-synchronization-model-for-various-lms-over-the-network?r=fajar.purnama
- https://hive.blog/computers/@fajar.purnama/compatible-course-content-synchronization-model-for-various-lms-over-the-network?r=fajar.purnama
- https://0fajarpurnama0.wixsite.com/0fajarpurnama0/post/compatible-course-content-synchronization-model-for-various-lms-over-the-network
- http://0fajarpurnama0.weebly.com/blog/compatible-course-content-synchronization-model-for-various-lms-over-the-network
- https://0fajarpurnama0.cloudaccess.host/index.php/9-fajar-purnama-academics/73-compatible-course-content-synchronization-model-for-various-lms-over-the-network